

Why I Write Dirty Code: Code Quality in Context
by Adam Tornhill, October 2019
I used to obsess about code quality earlier in my career. My experience indicates that I'm in good company here; a lot of us developers spend so much time growing our programming skills, and that kind of drive comes from intrinsic motivation. We care about what we do, and we want to do it well.
However, over the past decade I have noticed a change in how I approach code quality. I still consider code quality important, but only in context. In this article I want to share the heuristics I use to decide when high-quality code is called for, and when we can let it slip. It's all about using data to guide when and where to invest in higher code quality, and how it can be a long-term saving to compromise it. Let's start by uncovering the motivation for investing in code quality.
Code quality only matters in context
Code quality is a broad and ill-defined concept. To me, code quality is all about understandability. The reason being that code is read exceedingly more often than it's modified. In fact, most of our development time is spent trying to understand existing code just so that we know how to change it. We developers don't really write code. Our primary task is to read code, and the easier our code is to reason about, the cheaper it is to modify.
Now, let's pretend for a moment that we know that a particular piece of code will never ever be modified again. Would that change how you write that code? It should, at least in a world where business factors like time to market matter. So what would we do differently in this hypothetical scenario? Well, code comments would be the first thing to go -- the machine doesn't care about them anyway, and since the code won't ever be touched again, comments don't serve any real need. The same goes for design principles like loose coupling, high cohesion, and DRY -- none of those matter unless we have to revisit the code again.
Of course, quick and dirty code is all fun and games until we need to revisit it, understand it, and modify it. That's where the costs come. These delayed costs may be much higher than what it would have required to design the code properly in the first place, simply because we need to re-learn a part of the solution domain that is no longer fresh in our head. Since we cannot know up front if our code will be modified again or not, we learn to err on the safe side; better to make all code as clean as possible. That way we avoid unpleasant future surprises.
With that reservation, I will claim that doing a quick and dirty solution is almost always a faster short-term solution (before you burn the heretic, please note that I emphasized short-term). But could it also be a viable long-term saving? Can we trade quality for speed in the long run as well? It turns out that we can in certain situations.
When I reason about code, I'm not only looking at the code. I have just as much interest in understanding its temporal characteristics and trends, which is data we can mine from version-control history. The key concept I use for code quality decisions is hotspots.
A hotspot is code with high development activity and frequent churn. It's code that's worked on often, and hence code that has to be read and understood frequently, potentially by multiple authors. Here's an example from React.js, and a link to the interactive hotspot map:
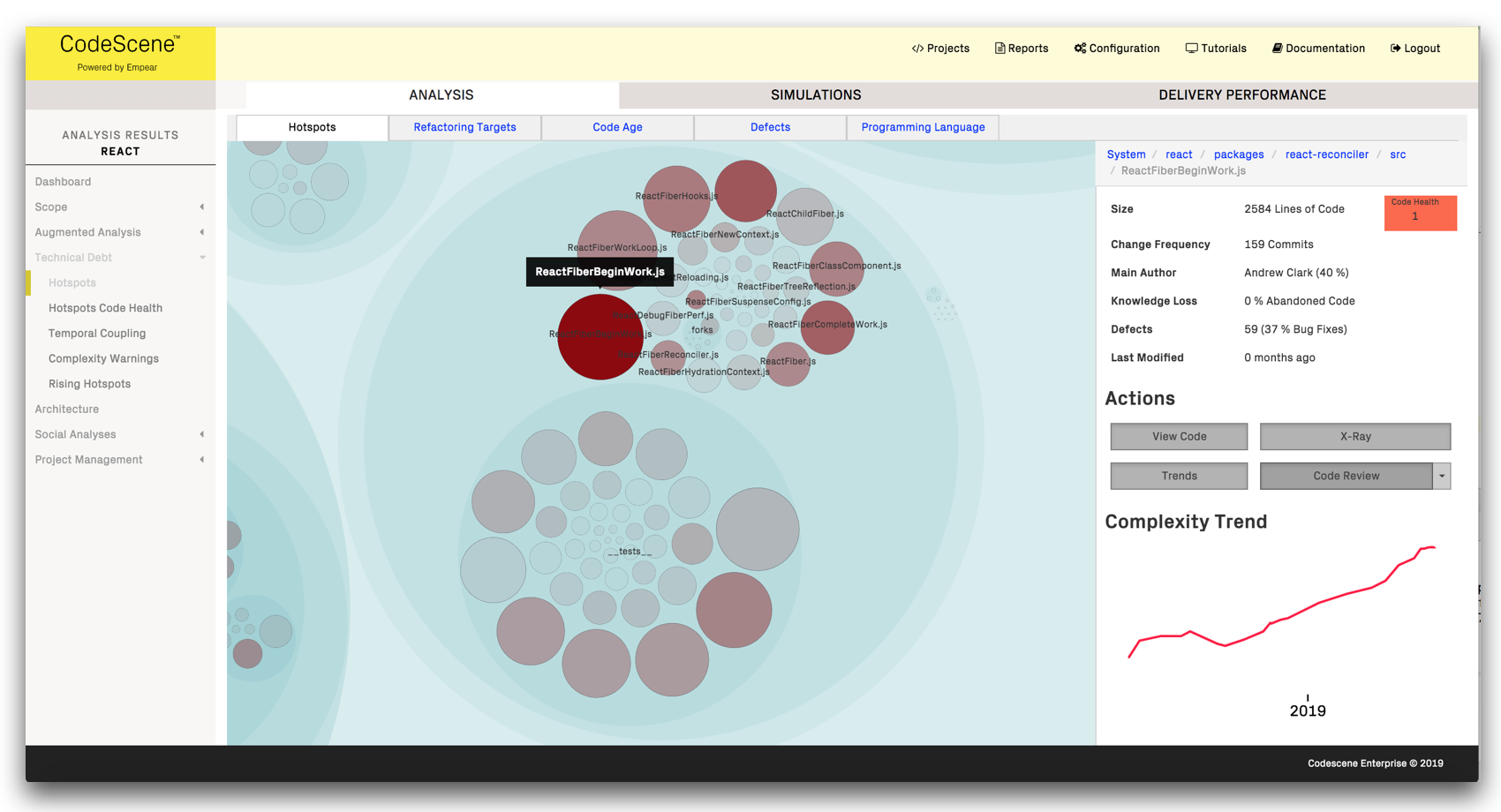
The interesting thing with hotspots is that they make up a relatively minor part of the code, often just 1-3% of the total code size. However, that small portion of the code tends to attract an unproportional amount of development activity. This becomes apparent if we plot the change frequency of each file in a codebase:
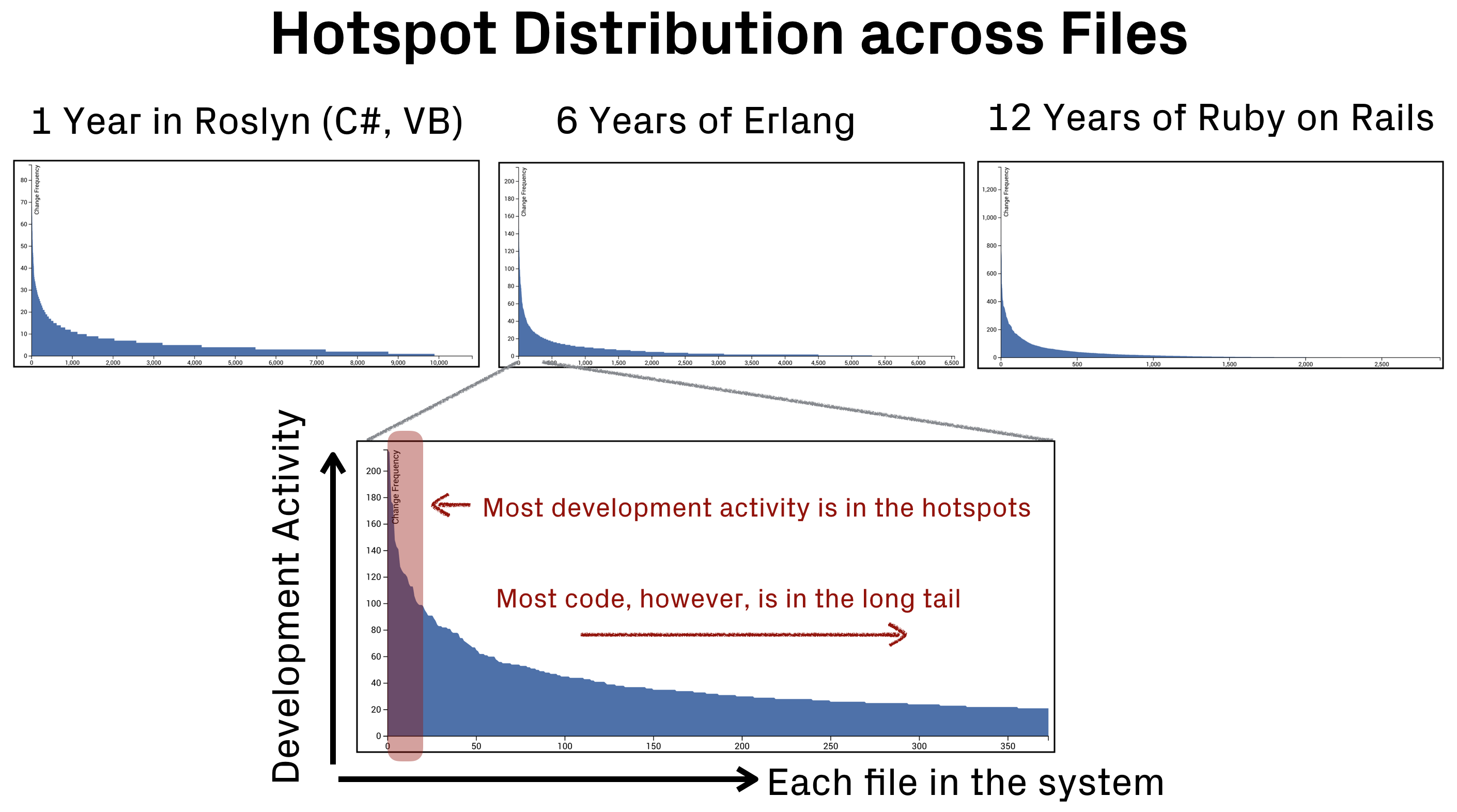
As you see in the preceding figure, most of your code is likely to be in the long tail. That means it's code that's rarely if ever touched. The hotspots, on the other hand, just make up a small part of the code but attract most of the development work.
This implies that any code quality issues or technical debt in the hotspots, however minor, are likely to be expensive. Really expensive. Since the code is worked on so often, the additional costs in understanding the code and in making sure it doesn't break, multiply quickly. This is where code quality matters the most.
I have used hotspot analyses in my daily work for the past 10 years. It's been a real game changer that I'm taking full advantage of. Here's how: occasionally, I need to expand or tweak a feature that's been stable for a long time, so I find myself operating in the long tail of change frequencies. To me, that's an opportunity to make the bet that the code will continue to remain stable. You see, code frequently turn into hotspots because it implements a particularly volatile area of the domain where requirements are evolving. Stable code usually represent stable parts of the domain too. That allows me to take short cuts.
For example, when working on code in the long tail I might realize that my new code is similar to some existing responsibility. So I copy-paste the original and tweak the copy to do what I want. Or I decide to add one more parameter to a function instead of looking for a concept to encapsulate. Or maybe I decide to squeeze in an extra if-statement in already tricky code. Yes, there's truly no limit to the sins I commit. But I only compromise quality in the long tail, and I only do it if I estimate that it will save me time.
On the other hand, once I work in hotspots, I'm well aware that the code will be worked on again; the best prediction of future activity is the code's history. So I take care in designing the code, and I often start by refactoring the existing solution to get a better starting point. Not only will this make life simpler for my colleagues; my future self is going to love me as well.
Take calculated risks
Before you walk into your manager's office to claim that this crazy Swedish programmer claims that we can write crappy code and benefit from it
, I think it's only fair to point out that I do have some rules to control the risk. It has become sort of an informal process and safety-net that guides me in my day job.
First of all, I know exactly how healthy my code is. I know the code health of each module in the codebase where I work thanks to CodeScene. CodeScene's Code Health metric was heavily researched and designed precisely for estimating how hard code would be for a human to understand. The code health metric doesn't care about the subjective stuff, like coding style or if a public constructor should lack a comment, but instead aims to catch the properties of code that really matter for maintainability.
Knowing the health of your code -- at any time -- is key. Once you have that knowledge, you can start to use technical debt in its original sense. That is, you can take on technical debt strategically. And if you balance the amount of debt you take on based on the hotspot criteria, then it might even become an interest free loan. There might be a free lunch after all, it just requires data.
When using the code health metric, I also tend to emphasize trends over absolute values. I use this to put a quality bar on any code that I touch. Should some code slide down and decline in health, then that might be a sign I've gone too far and need to pay down the accumulated debt. To make it actionable, I run these checks in a CI/CD pipeline (you can read more on how this works on my other blog).
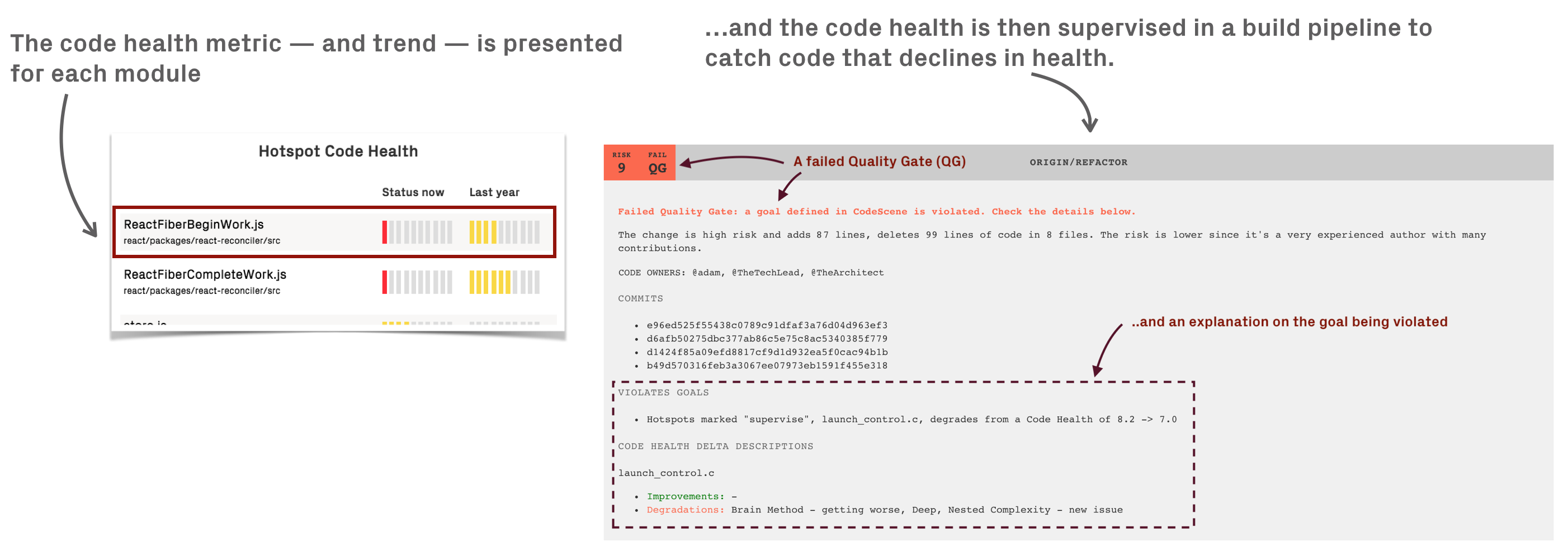
Finally, I tend to write a test for most new code. When operating in the long tail, I might not put the full effort into making the code easily testable, but I do like to leave a test as a safety-net for my future self.
The perils of improving existing code
So far I've talked about the economics of knowing when -- and when not -- to invest in code quality. But there's a different perspective too, and it's an argument about correctness. You see, clean code that doesn't work is rarely rewarded. And this is where it gets interesting. It turns out that there's a correlation between old, stable code and correctness.
I covered this in Software Design X-Rays under the title Your Best Bug Fix Is Time
. In that section, I reference research that compares modules of different age. That is, the time since their last modification. That research finds that a module which is a year older than a similar module has roughly one-third fewer defects.
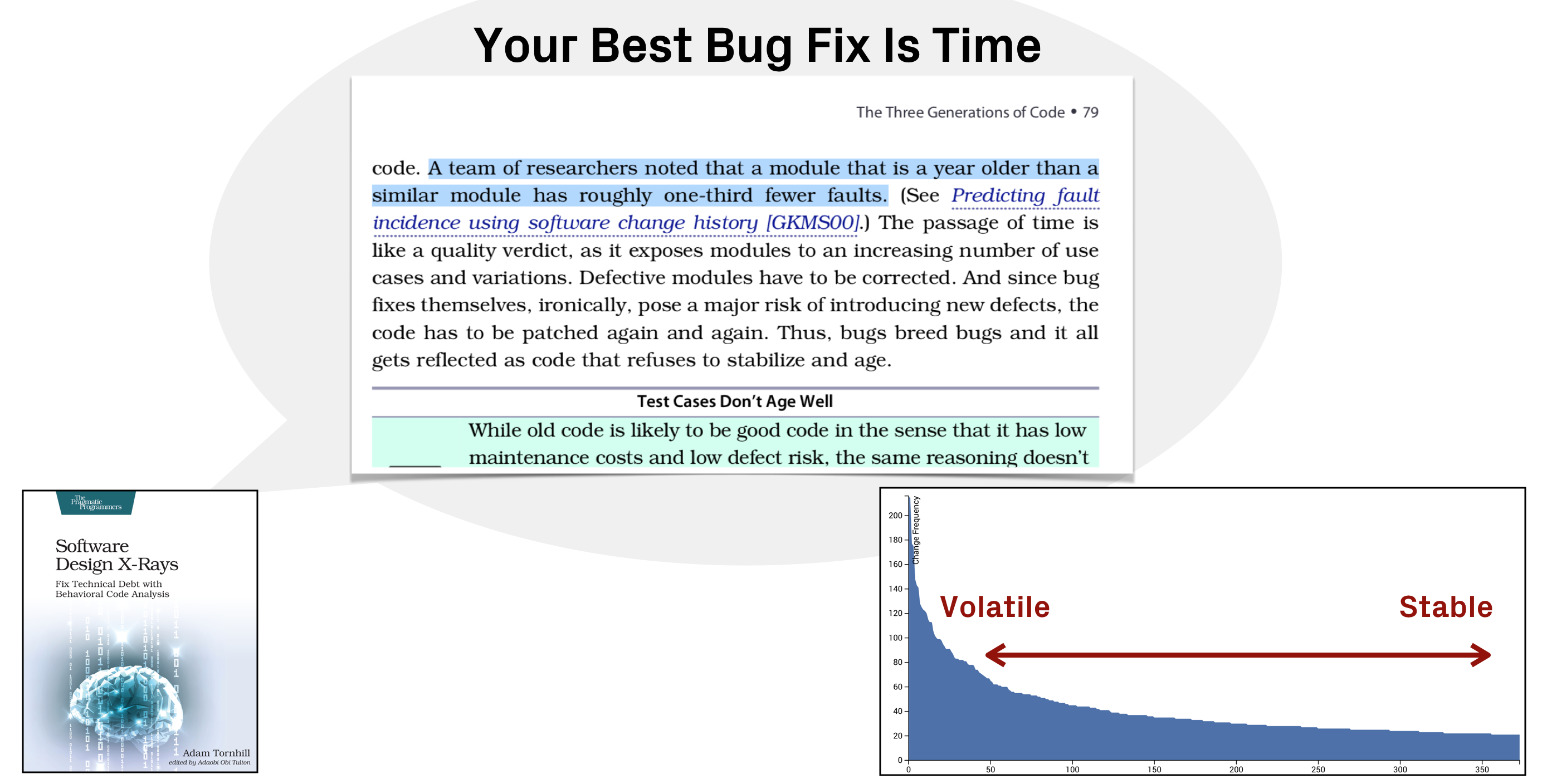
Code stabilizes for different reasons. One might be that it's dead code, which means it can be safely deleted (always a win). Or it might become stable because it just works and does its job. Sure,the code may still be hard to understand, but what is there is likely to have been debugged into functionality. It's been battle tested and it just works. Using hotspots, you can ensure it stays that way.
This correctness perspective is the main reason why I would like to put the Boy Scout Rule into context too; should we really be boy scouting code in the long tail? Code that we haven't worked on in a long time, and code that we might not touch again in the foreseeable future. I would at least balance the trade-offs between stabilizing code and refactoring it, and I tend to value stability higher. But again, it's a contextual discussion that cannot -- and shouldn't -- be taken as a general rule applicable to all code. All code isn't equal.
Code quality as a lever
I rarely use clean code
as a term, simply because it suggests an absolute that I don't think exist, and the opposite -- dirty code -- is by definition unattractive. That said, I do appreciate much of the work by the clean code movement, I follow it closely, and I learn from it. I do think that the movement has pushed our industry in a good direction.
My point is simply that good
is contextual. And following a principle to the extreme means a diminishing return; we spend time polishing code with little pay off, and that's time we could have been spent on activities that actually benefit our business. By making contextual decisions, guided by data from how our code evolves, we can optimize our efforts and view code quality as a design option that we might or might not need in specific situations. It all depends.
About Adam Tornhill
Adam Tornhill is a programmer who combines degrees in engineering and psychology. He's the founder of Empear where he designs the CodeScene tool for software analysis. He's also the author of Software Design X-Rays: Fix Technical Debt with Behavioral Code Analysis, the best selling Your Code as a Crime Scene, Lisp for the Web, Patterns in C and a public speaker. Adam's other interests include modern history, music, and martial arts.
Past Favourites
- Lisp for the Web
- tinch++: Interfacing Erlang from C++
- Let Over Lambda
- Solving FizzBuzz with C++ compiler error messages
- Structure and Interpretation of Computer Programs
- The Case Against XP
- Design in Test-Driven Development
- Coders at Work
- A Whole New Mind
- Objects for State (pdf)
- Pragmatic Thinking and Learning: Refactor Your Wetware
![]()




